After having solved a previous networking issue of the control board, I’m currently running into another kind of networking trouble: When trying to download large amounts of data (here it’s a container > 435 MB in size, but I need it urgently), everything seems to work fine for some 10 minutes, but then suddenly, the network connection dies, and I get a bunch of DMA timeouts on the control board console:
[ 1532.020301] miop 0000:06:00.0: DMA timeout, restart DMA controller.
[ 1533.059083] miop 0000:06:00.0: DMA timeout, restart DMA controller.
[ 1534.099126] miop 0000:06:00.0: DMA timeout, restart DMA controller.
[ 1537.620021] miop 0000:06:00.0: DMA timeout, restart DMA controller.
And this is what I get on the console of the node the container is for (abridged, irrelevant messages removed):
mixtile@blade3n1:~$ sudo cephadm bootstrap --mon-ip $MYIP
[…]
Host looks OK
Cluster fsid: 89e84929-c54d-11f0-9c36-0e281c59af8c
Verifying IP 10.20.0.13 port 3300 ...
Verifying IP 10.20.0.13 port 6789 ...
Mon IP `10.20.0.13` is in CIDR network `10.20.0.0/24`
Mon IP `10.20.0.13` is in CIDR network `10.20.0.0/24`
Internal network (--cluster-network) has not been provided, OSD replication will default to the public_network
Pulling container image quay.io/ceph/ceph:v19...
Non-zero exit code 1 from /usr/bin/docker pull quay.io/ceph/ceph:v19
/usr/bin/docker: stdout v19: Pulling from ceph/ceph
/usr/bin/docker: stdout 4d1c9f96c84f: Pulling fs layer
/usr/bin/docker: stdout d0eb5eb08af7: Pulling fs layer
/usr/bin/docker: stdout d0eb5eb08af7: Waiting
[…]
/usr/bin/docker: stdout 4d1c9f96c84f: Retrying in 5 seconds
/usr/bin/docker: stdout 4d1c9f96c84f: Retrying in 4 seconds
/usr/bin/docker: stdout 4d1c9f96c84f: Retrying in 3 seconds
/usr/bin/docker: stdout 4d1c9f96c84f: Retrying in 2 seconds
/usr/bin/docker: stdout 4d1c9f96c84f: Retrying in 1 second
/usr/bin/docker: stderr read tcp 10.20.0.13:40398->212.6.82.160:443: read: connection reset by peer
Error: Failed command: /usr/bin/docker pull quay.io/ceph/ceph:v19
***************
Cephadm hit an issue during cluster installation. Current cluster files will be deleted automatically.
[…]
***************
Deleting cluster with fsid: 89e84929-c54d-11f0-9c36-0e281c59af8c
ERROR: Failed command: /usr/bin/docker pull quay.io/ceph/ceph:v19
I have already improved the config of the Squid proxy on the control board by adding extra cache space:
61 # Uncomment and adjust the following to add a disk cache directory.
62 cache_dir aufs /var/cache/squid 8000 16 256
63 cache_mem 180 MB
64
65 # Maximum object size
66 maximum_object_size 1024 MB
67 maximum_object_size_in_memory 16 MB
68
69 # How objects stored in cache are replaced
70 cache_replacement_policy heap LFUDA
71 memory_replacement_policy heap GDSF
Apparently, the control board gets somehow overwhelmed by the network traffic, but I’m not sure whether the problem liess on the internal network link, or the external one. At least the board has more than enough RAM. Here is what netdata says:
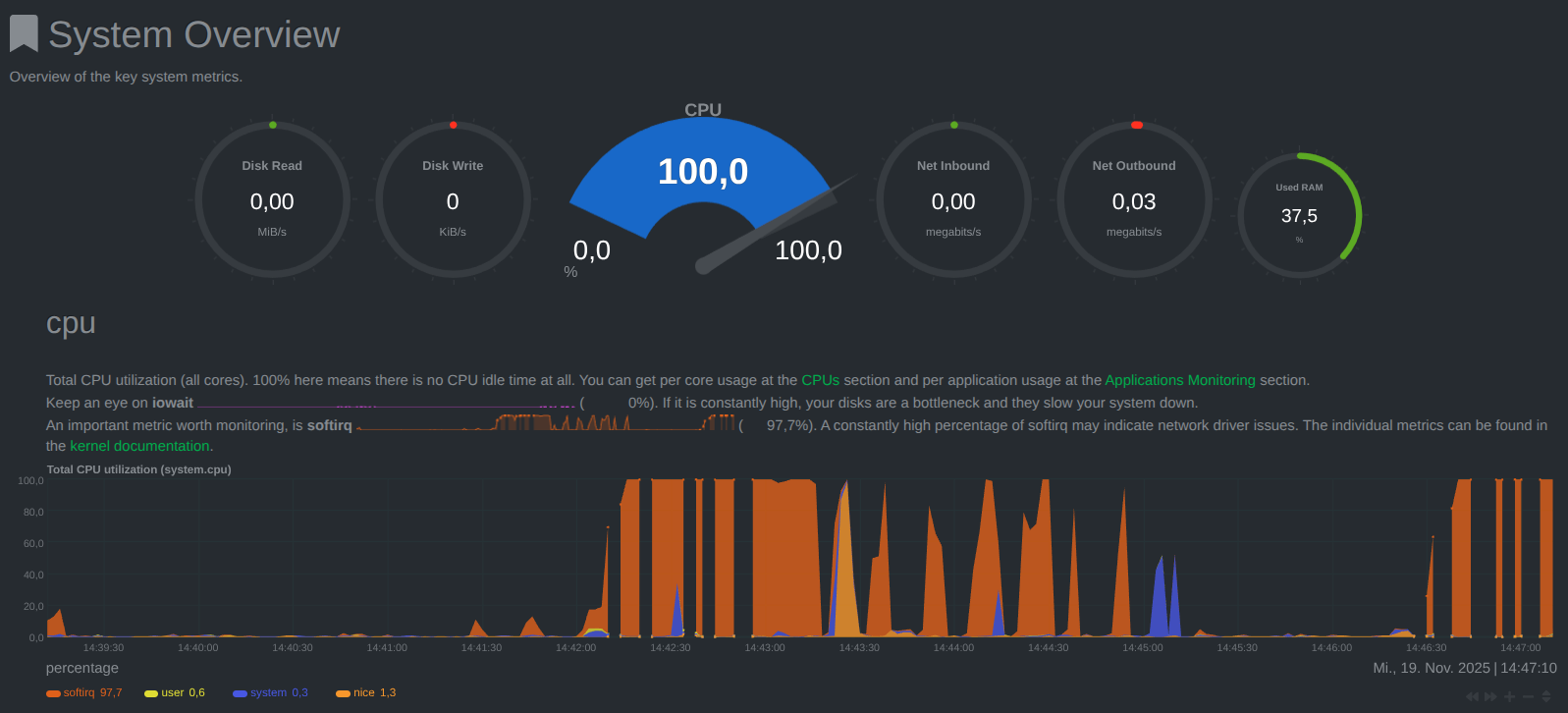
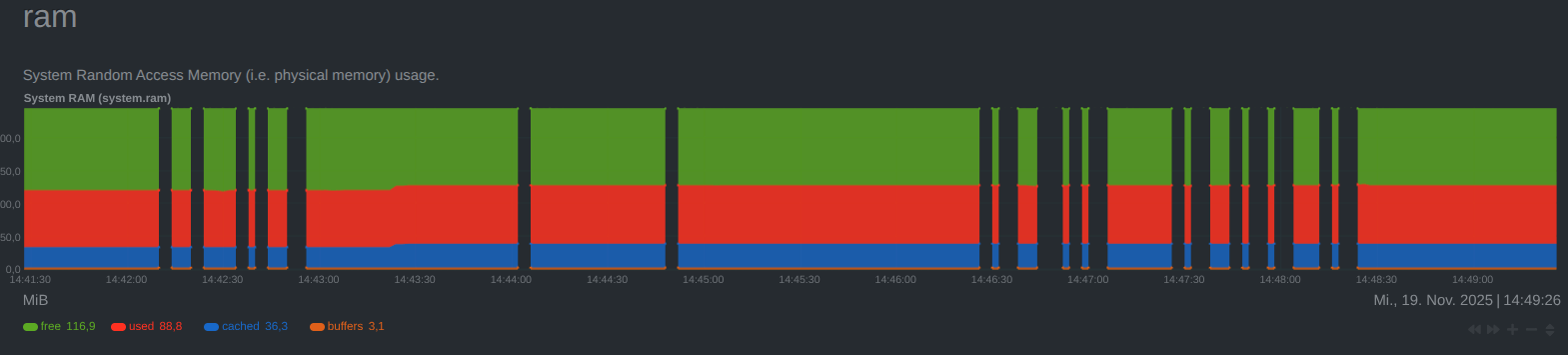
What’s wrong here? Any idea on how to solve (or, at least, to circumvent) it?
UPDATE:
After another try, not only the cluster’s network died, but apparently the control board crashed and also made the nodes crash! See the uptime from uptime just a munite after the crash:
mixtile@ClusterBox:~$ client_loop: send disconnect: Broken pipe
╭─jacek@epica ~
╰─➤ ssh -l mixtile ClusterBox 255 ↵
Enter passphrase for key '/home/jacek/.ssh/id_ed25519':
mixtile@ClusterBox:~$ uptime
16:06:32 up 1 min, load average: 1.42, 0.55, 0.19
mixtile@ClusterBox:~$
Why does a crash of the control board also carries away the nodes? This must not happen!